YamFlow¶
This specification is maintained as a GitHub project. Please leave your feedback on GitHub Issues.
Introduction¶
YamFlow proposes a reference workflow for the machine learning (ML) development lifecyle. This reference workflow is aimed to provide a canonical taxonomy for practitioners to understand and communicate the activity sequences and the data flows typically involved in a ML process. In addition, YamFlow also serves as the baseline for YAM AI Machinery to design ML programming frameworks for developing interoperable and composable ML tasks.
YamFlow Overview¶
Fig. 1 shows the flowchart of YamFlow, which specifies the overall process of a typical ML implementation in the design time and run time. Although the actual processes of different ML implementations may vary, the activity sequences and data flows should largely resemble YamFlow.
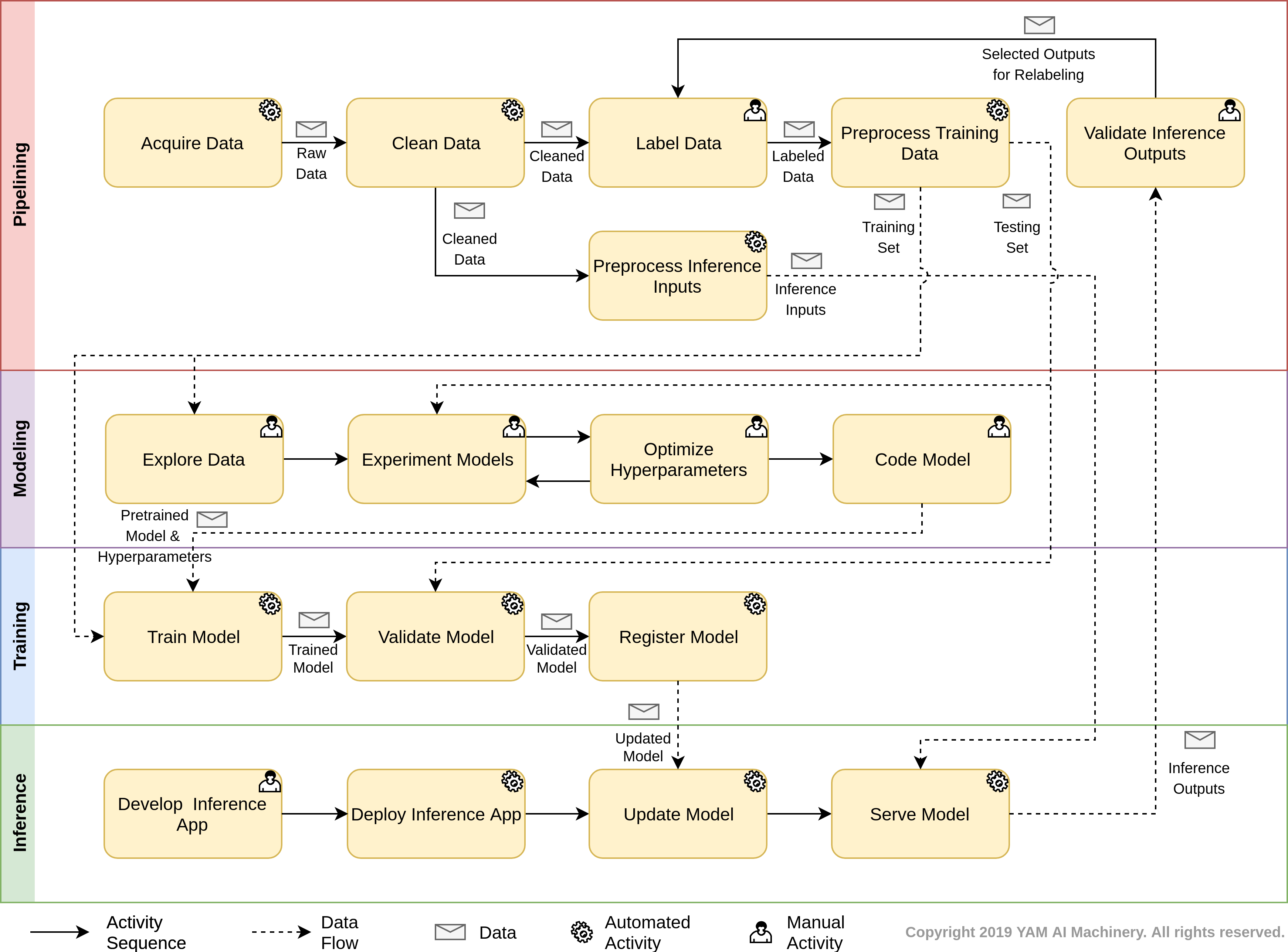
Fig. 1 YamFlow Chart.
YamFlow consists of the following work streams:
- Pipelining specifies the work stream for building the data pipelines for ML modeling, training, and inference in the development time.
- Modeling specifies the work stream for exploring the data, and design and code the ML model in the design time.
- Training specifies the work stream for training the coded model in the recurrent training time.
- Inference specifies the work stream for deploying the inference application and serve the trained model in the runtime.